
TÜLU 3是艾伦人工智能研究所(Ai2)推出的一系列开源指令遵循模型,包括8B和70B两个版本,未来计划推出405B版本。模型在性能上超越Llama 3.1 Instruct版本,提供了详细的后训练技术报告,公开数据、评估...
网站首页 > AI工具 第9页
-

-

Markdown-to-Image是开源的Markdown 转为海报的编辑器,作为React组件能将Markdown文本内容转换成图像,适用于创建社交媒体帖子、海报和其他视觉内容。工具支持多种输出格式,包括海报、图片、引用、...
-
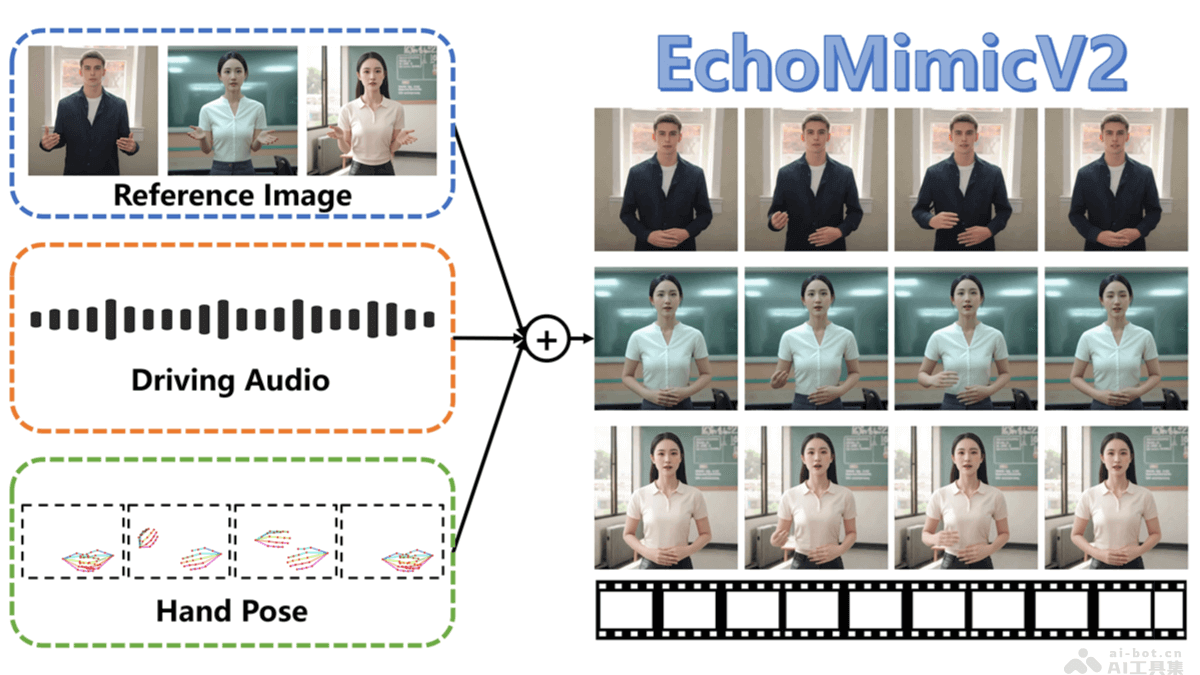
EchoMimicV2是蚂蚁集团推出的半身人体动画(数字人)生成方法,基于参考图片、音频剪辑和手部姿势序列生成高质量动画视频,确保音频内容与半身动作的一致性。EchoMimicV2在前代 EchoMimicV1 生成逼真人头...
-

AutoVFX是先进的物理特效框架,是伊利诺伊大学香槟分校研究团队推出的,能根据自然语言指令自动创建真实感和动态的视觉特效(VFX)视频。框架集成神经场景建模、基于大型语言模型(LLM)的代码生成和物理模拟技术,实现照片级逼...
-
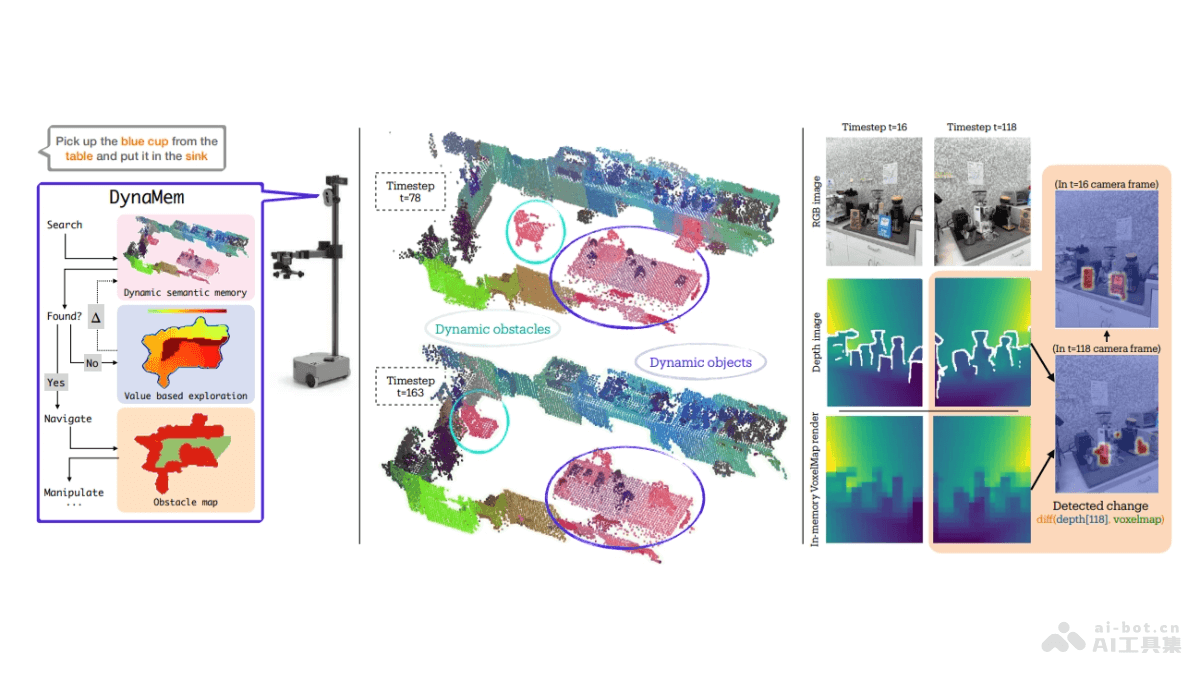
DynaMem是纽约大学和Hello Robot推出的动态空间语义记忆系统,专为开放世界中的移动操作设计。基于维护一个特征点云作为机器人记忆,处理环境中的动态变化,如物体的添加和移除。当接收到新的RGBD观测时,DynaMe...
-

Add-it是NVIDIA推出的无需训练的图像编辑技术,能根据文本指令在图像中添加对象。这项技术基于扩展扩散模型的注意力机制,整合场景图像、文本提示和生成图像的信息,实现结构一致性和自然的对象放置。...
-

LTXV是Lightricks推出的开源AI视频生成模型,全称为LTX Video。能在4秒内生成5秒的高质量视频,速度超过观看速度。基于2亿参数的DiT架构,确保帧间平滑运动和结构一致性,解决了早期视频生成模型的关键限制。...
-
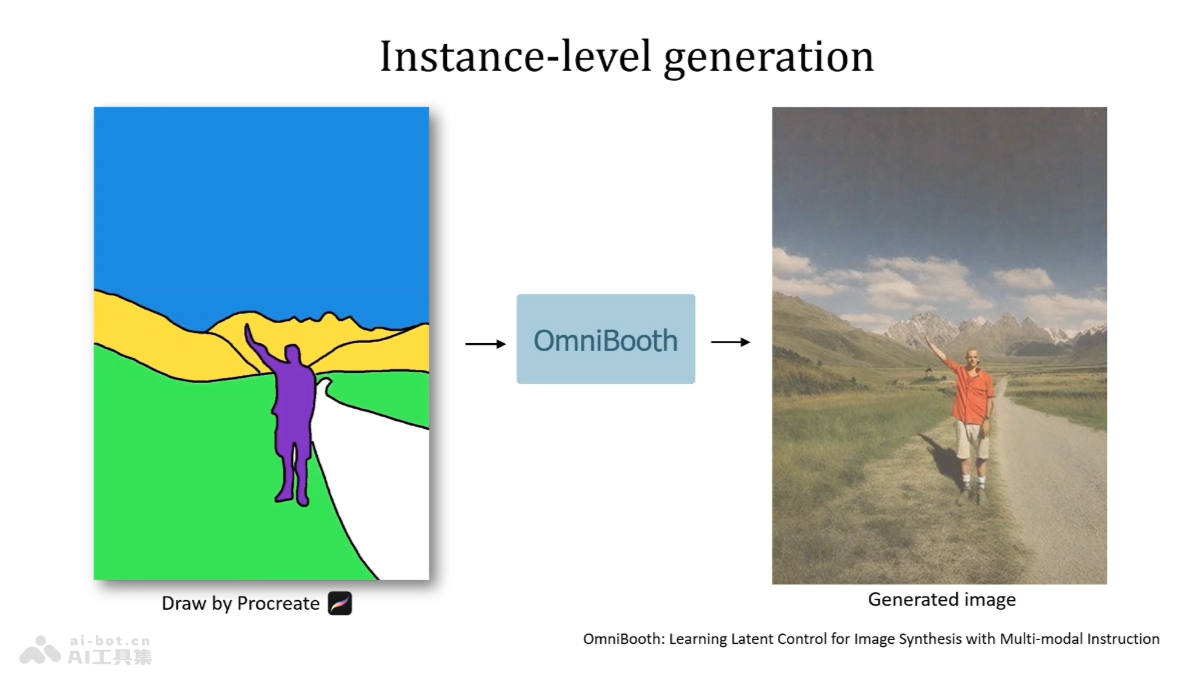
OmniBooth是华为诺亚方舟实验室和港科大研究团队共同推出的图像生成框架,支持基于文本提示或图像参考进行空间控制和实例级定制。框架用用户定义的掩码和相关联的文本或图像指导精确控制图像中对象的位置和属性,提升文本到图像合成...
-

MVPaint是腾讯PCG 、上海AI LAB、南洋理工大学S-Lab、清华大学共同推出的3D纹理生成框架,基于同步多视角扩散技术实现高分辨率、无缝且多视图一致的3D纹理生成。MVPaint包含三个核心模块:同步多视角生成(...
-

DreamPolish是Zhipu AI、清华大学和北京大学推出的文本到3D生成模型,基于两阶段方法改进复杂对象的精细几何结构和高质量纹理的生成。第一阶段用多种神经表示逐步细化几何形状,基于抛光阶段改善表面细节。第二阶段用领...
