
DINO-X是IDEA研究院推出的通用视觉大模型,具备开放世界对象检测与理解能力。支持文本、视觉和定制提示,能识别图像中的任何对象而无需用户提示。基于超过1亿样本的Grounding-100M数据集,DINO-X在COCO、...
网站首页 > AI工具 第10页
-

-

The Matrix是与电影同名的、首个AI基础世界模拟器,是全华人团队推出的(作者分别来自阿里巴巴、香港大学、滑铁卢大学和加拿大AI研究机构Vector Insititute)。The Matrix能生成无限长、高保真72...
-

AutoConsis是UI内容一致性智能检测,是美团技术团队与复旦大学联合推出的。工具基于深度学习和大型语言模型自动识别和提取界面中的关键数据,检测并识别数据间的不一致性问题。AutoConsis能提升用户体验,减少因数据展...
-
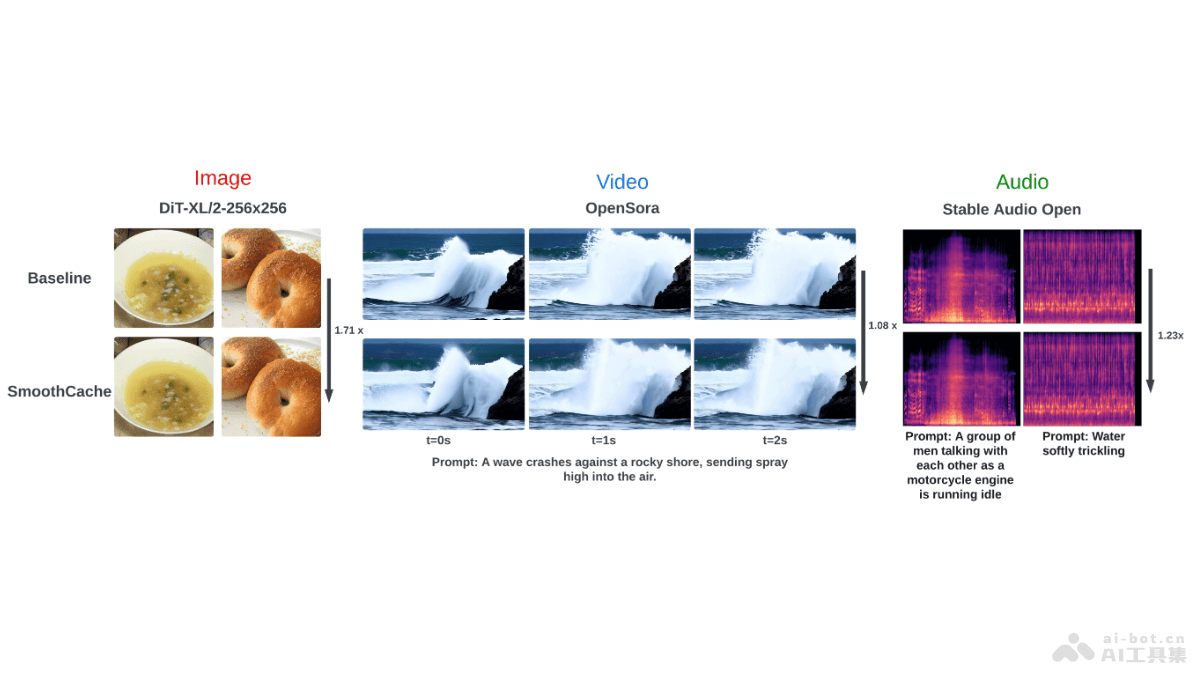
SmoothCache 是用在Diffusion Transformers (DiT)模型的通用推理加速技术,是 Roblox 和女王大学的研究团队推出。基于分析相邻扩散时间步的层输出相似性,自适应地缓存和重用关键特征,减少...
-

In-Context LoRA是阿里巴巴通义实验室推出的基于扩散变换器(DiTs)的图像生成框架,用模型的内在上下文学习能力,最小化调整激活模型的上下文生成能力。这种方法无需修改原始模型架构,只需对训练数据进行微调,就能适应...
-

OmniEdit是先进的图像编辑技术,通过结合多个专家模型的监督来训练一个通用模型,处理多种图像编辑任务。能处理不同纵横比的图像,七种不同的图像编辑任务,包括对象替换、移除、添加等,支持任意宽高比和分辨率。...
-
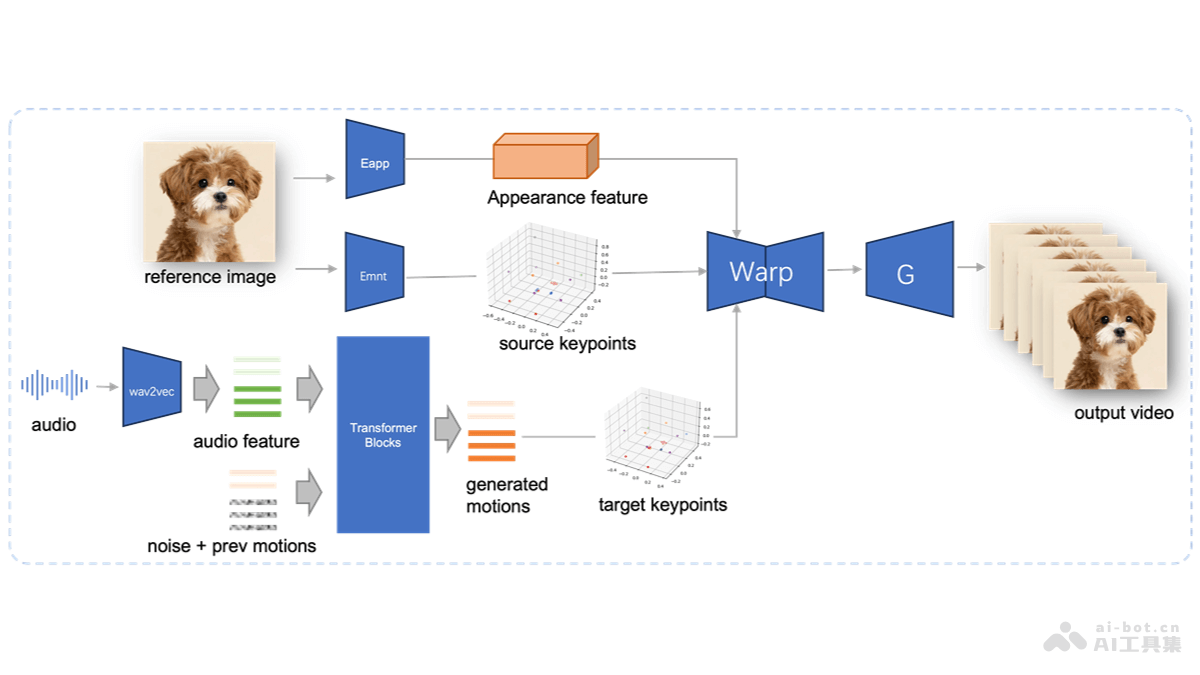
JoyVASA是京东健康国际公司开源的音频驱动的数字人头项目,基于扩散模型技术,根据音频信号生成与音频同步的面部动态和头部运动。JoyVASA能实现人物的唇形同步和表情控制,还扩展到动物头像的动画生成,在多语种支持和跨物种动...
-

FLUX Tools是黑森林实验室推出的一套模型工具,能增强基础文本到图像模型FLUX.1的控制性和可操作性。FLUX Tools包括FLUX.1 Fill(图像修复和扩展)、FLUX.1 Depth(基于深度图的结构引导)...
-

LaTRO(Latent Reasoning Optimization)是先进的框架,提升大型语言模型(LLMs)在复杂推理任务中的表现。基于将推理过程类比为从潜在分布中采样,用变分推断方法进行优化,LaTRO让模型自我改进...
-

AlphaQubit是谷歌推出基于AI技术的量子错误解码器,用深度学习架构Transformers识别和纠正量子计算中的错误。AlphaQubit基于精确的误差识别,助力量子计算机实现长时间、大规模的可靠计算,对于推动量子计...
