
OneDiffusion是AI2推出的多功能大规模扩散模型,能无缝支持双向图像合成和理解,涵盖文本到图像生成、条件图像生成、图像理解等多种任务。基于将所有条件和目标图像建模为序列“视图”训练,实现在推理时任意帧作为条件图像的...
-

-
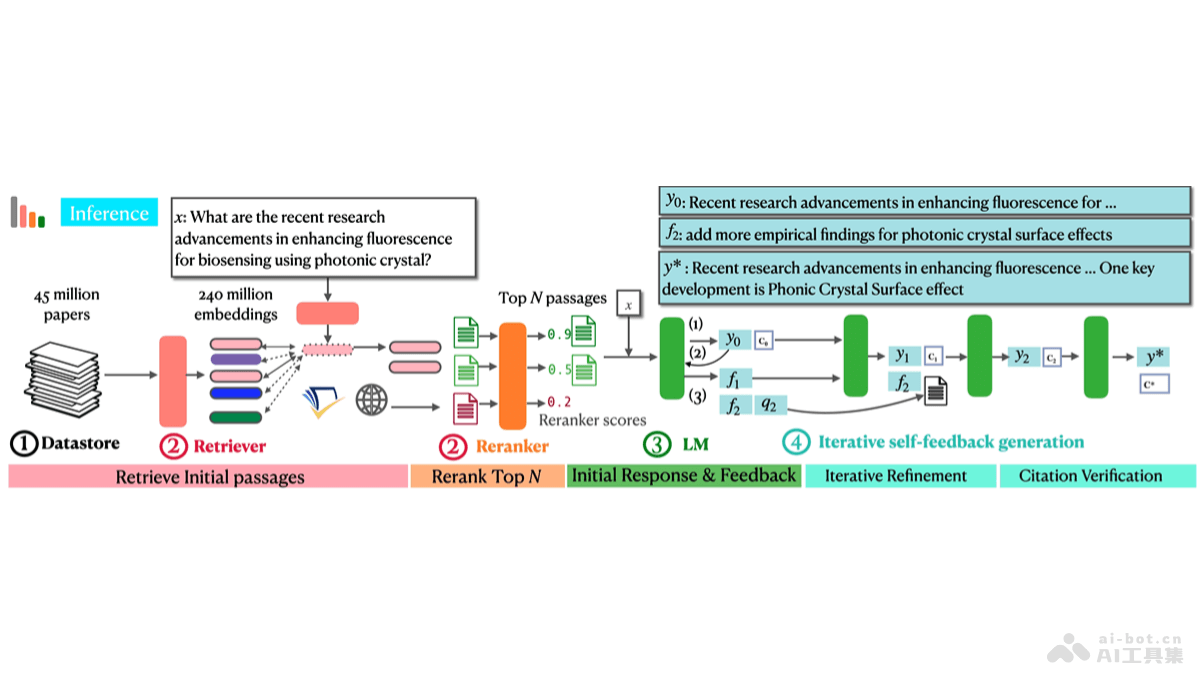
OpenScholar是华盛顿大学和艾伦AI研究所共同推出的检索增强型语言模型(LM),能帮助科学家基于检索和综合科学文献中的相关论文回答问题。系统用大规模的科学论文数据库,用定制的检索器和重排器,及一个优化的8B参数语言模...
-
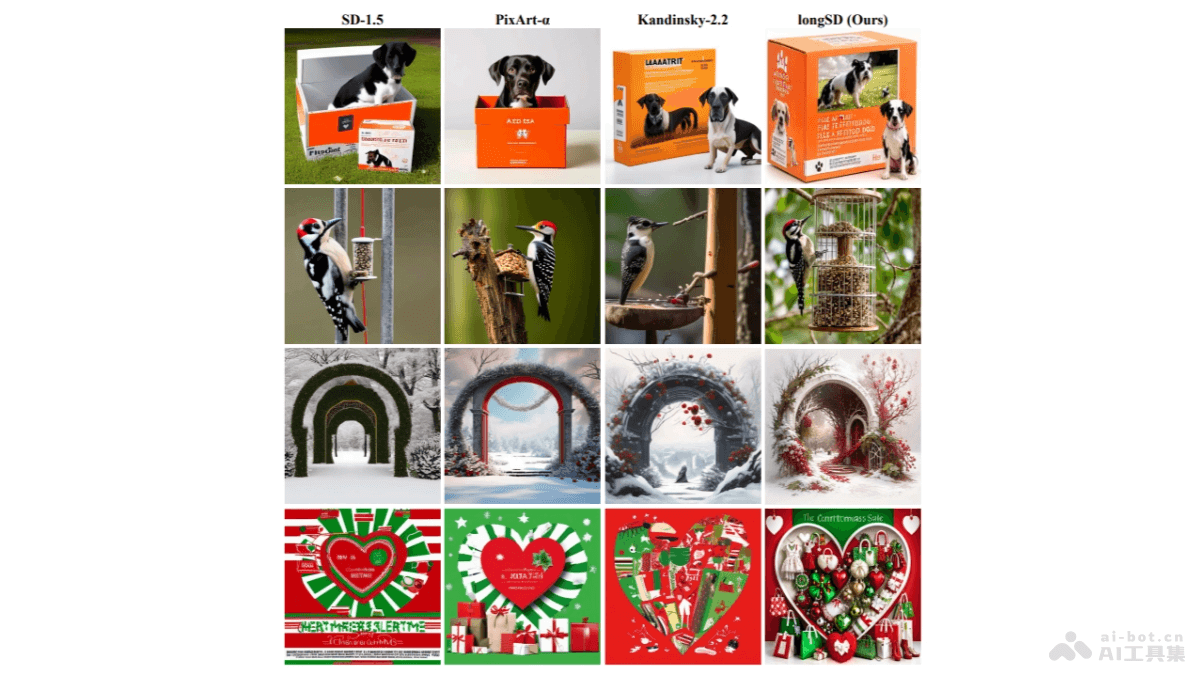
LongAlign是香港大学研究团队推出的文本到图像(T2I)扩散模型的改进方法,能提升长文本输入的对齐精度。LongAlign用段级编码技术,将长文本分割处理,适应编码模型的输入限制。同时引入分解偏好优化,基于区分偏好模型...
-

Teacher2Task是谷歌团队推出的多教师学习框架,引入教师特定的输入标记和重新构思训练过程,消除对手动聚合启发式方法的需求。框架不依赖聚合标签,将训练数据转化为N+1个任务,包括N个辅助任务预测每位教师的标记风格,及一...
-
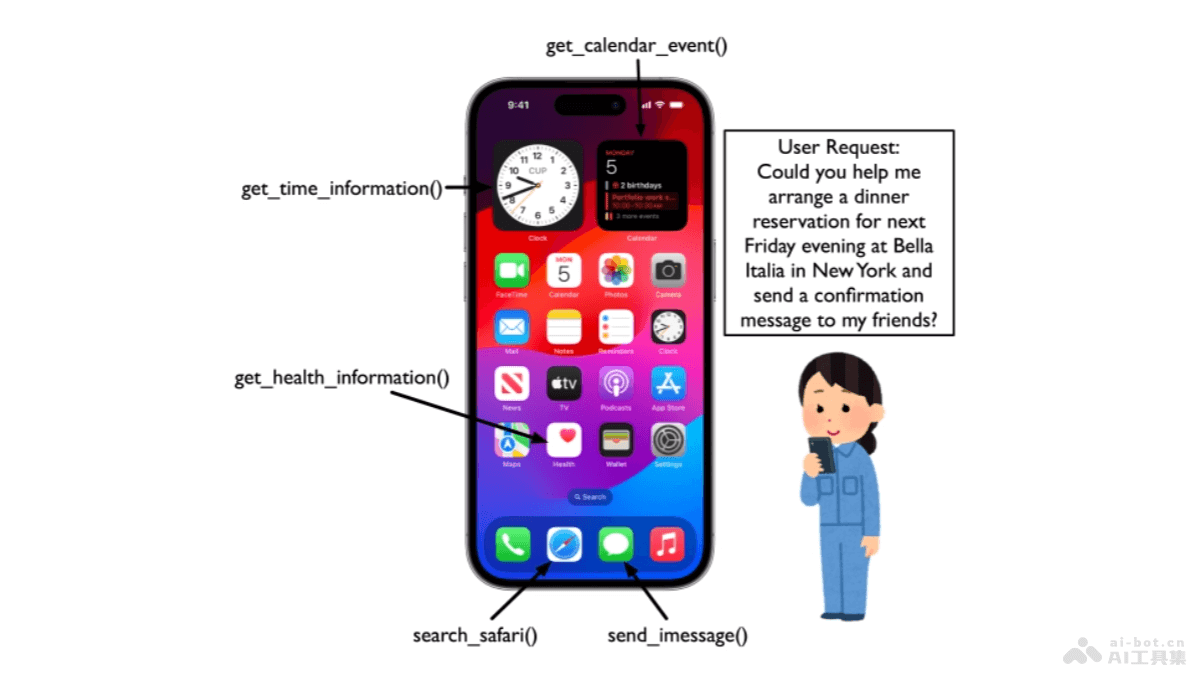
CAMPHOR是苹果团队推出的端侧小语言模型(SLM)多智能体框架,能提升移动设备的隐私保护和响应速度。框架基于在设备本地处理多个用户输入并进行个人上下文推理,确保用户隐私安全。CAMPHOR基于分层架构,其中高阶推理智能体...
-

Takin AudioLLM是喜马拉雅Everest团队推出的一系列高质量零样本语音生成模型,包括Takin TTS、Takin VC和Takin Morphing。模型用最新的大型语言模型技术,专注于有声书制作,能生成接近...
-

ACE(All-round Creator and Editor)是阿里巴巴集团Tongyi Lab推出的基于扩散变换器的全能图像生成和编辑模型。ACE引入长上下文条件单元(LCU)和统一条件格式,能理解和执行自然语言指令,...
-

AutoTrain(AutoTrain Advanced)是Hugging Face推出的开源无代码平台,能简化最先进模型的训练过程。支持用户无需编写代码即可创建、微调和部署自己的AI模型,只需上传数据即可训练自定义机器学习...
-
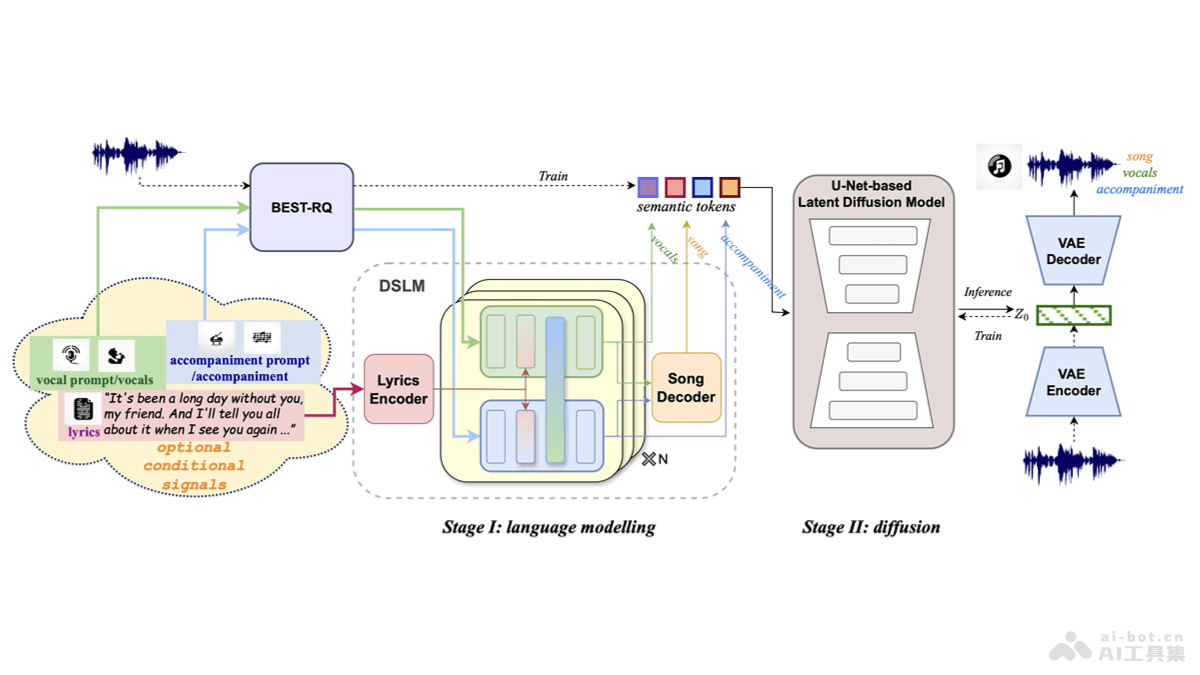
SongCreator是清华大学深圳国际研究生院、香港中文大学等机构推出的歌曲生成系统,能从歌词出发生成包含声乐和伴奏的完整歌曲。基于双序列语言模型(DSLM)和注意力掩码策略,理解和生成各种相关的歌曲生成任务,包括编辑和生...
-
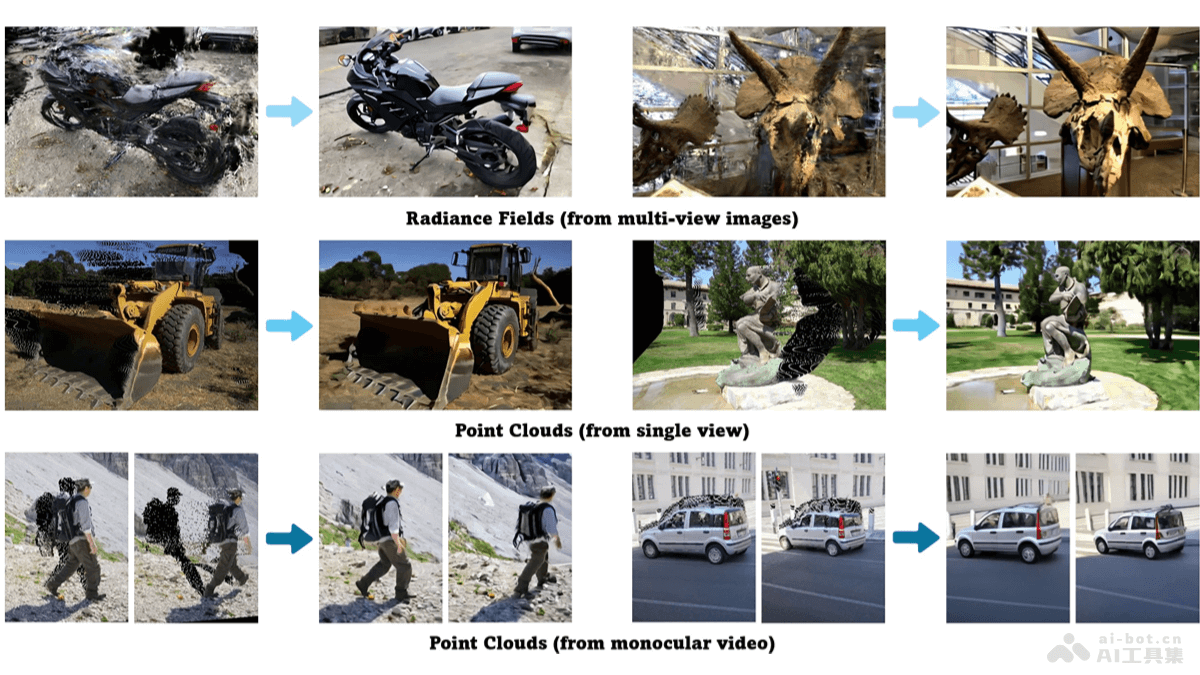
ViewExtrapolator是南洋理工大学、UCAS研究团队共同推出的新视角外推方法,基于稳定视频扩散(Stable Video Diffusion, SVD)的生成先验合成远超出训练视图范围的新视角。这种方法基于重新设...
