
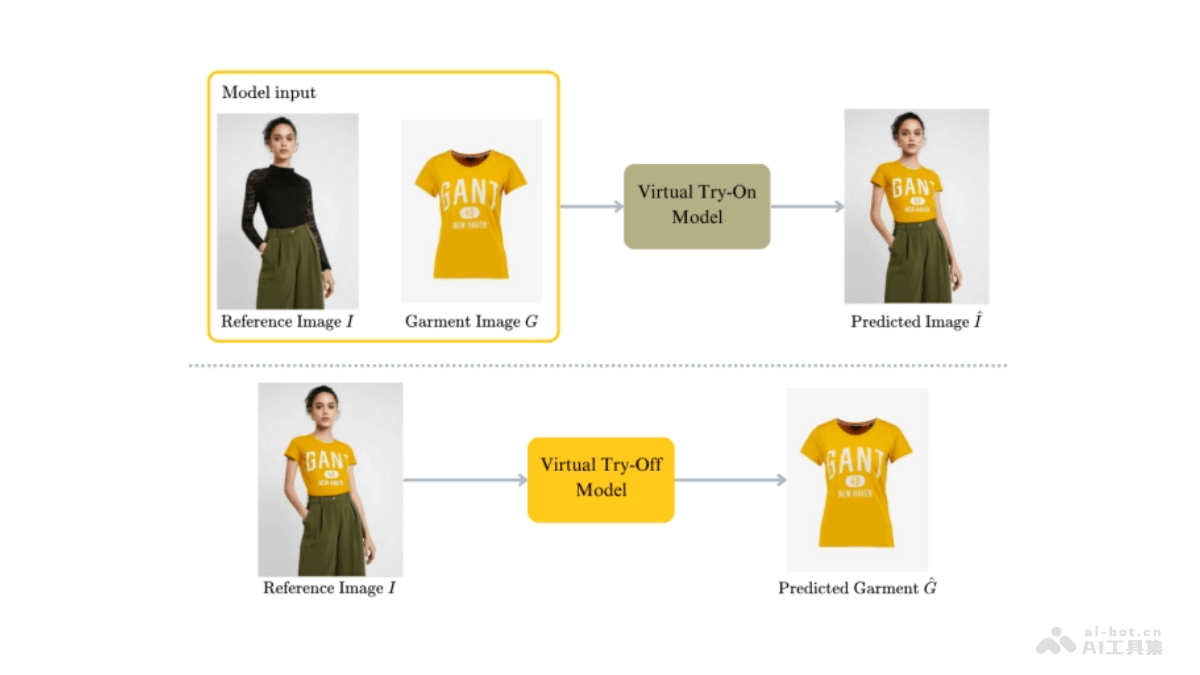
TryOffDiff(VTOFF)是基于扩散模型的新型虚拟试穿技术,用高保真服装重建实现虚拟试穿,专注于从单张穿着者照片生成标准化的服装图像。与传统的Virtual Try-On技术不同,TryOffDiff的目标是从参考图...
-
-

GLM-PC是智谱科技基于CogAgent视觉多模态模型开发的通用Agent,能模拟人类操作计算机,实现“无人驾驶”PC的技术探索。GLM-PC能执行预定会议、文档处理、网页搜索总结等任务,并支持远程和定时操作。GLM-PC...
-
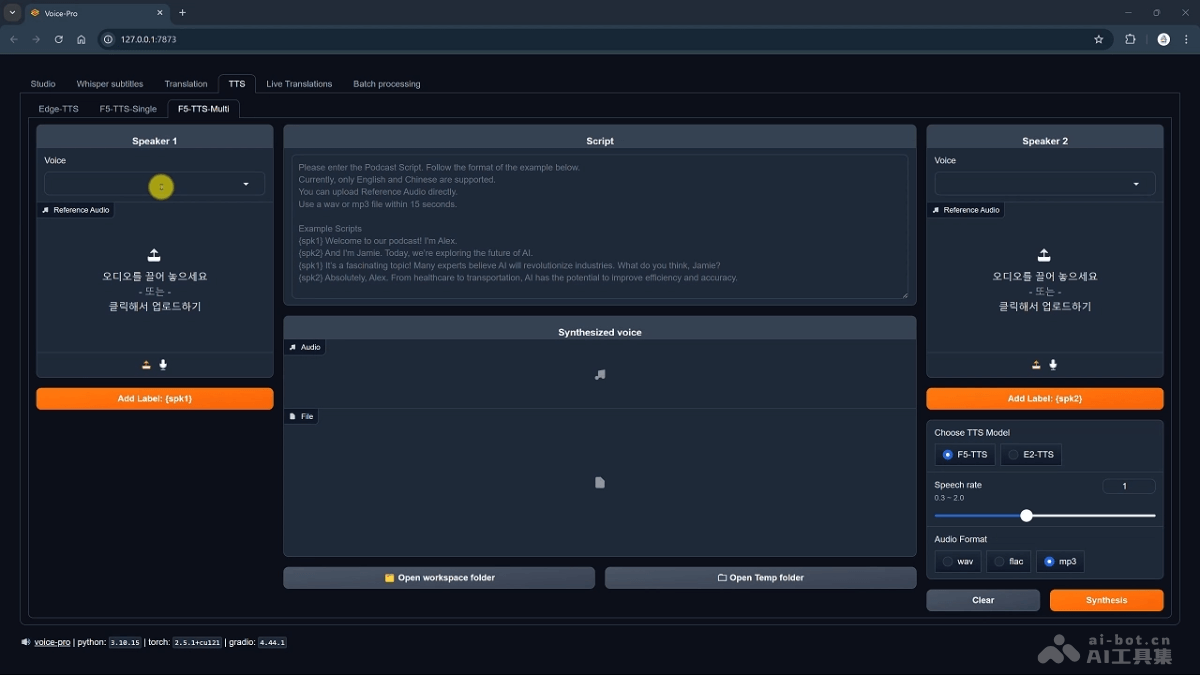
Voice-Pro是开源的多功能音频处理工具,集成语音转文字(STT)、文本转语音(TTS)、实时翻译、YouTube视频下载和人声分离等多种功能。工具支持超过100种语言,适用于教育、娱乐和商业等多个领域,为用户提供一站式...
-

Generative Omnimatte 是 Google DeepMind 等机构推出的视频编辑技术,能将视频智能分解为多个透明背景的RGBA图层,每个图层对应一个物体及其相关效果(如阴影、反射等)。这项技术无需绿幕或深度...
-
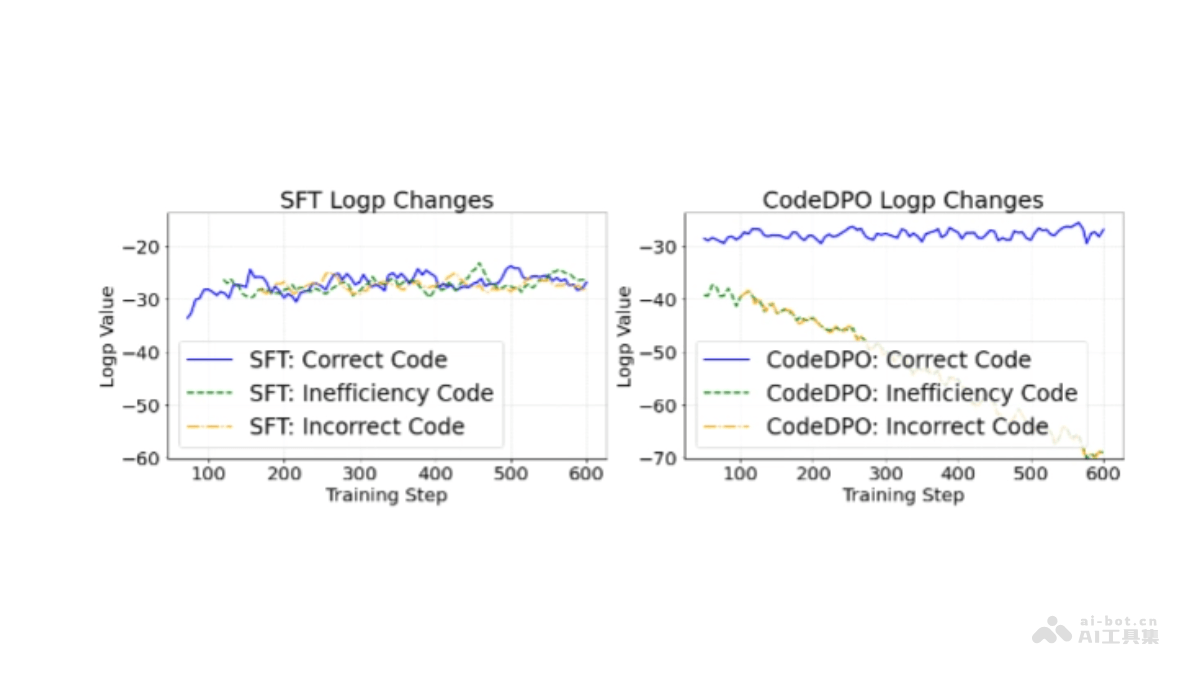
CodeDPO是北京大学与字节跳动合作推出的代码生成优化框架,能提升代码模型在正确性和效率方面的表现。框架基于自生成和验证机制,同时构建和评估代码及其测试用例,用PageRank算法迭代更新代码片段的排名,最终形成基于正确性...
-

Diffusion Self-Distillation(DSD)是创新的零样本定制图像生成技术,用预训练的文本到图像扩散模型自动生成数据集,并将其微调为能进行文本条件的图像到图像任务的模型。Diffusion Self-Di...
-

Open Materials 2024 (OMat24 是Meta推出的包含超过1.1亿个结构的密度泛函理论(DFT 计算的大型开放数据集,专注于无机材料的结构和成分多样性。附带预训练的图神经网络模型EquiformerV...
-
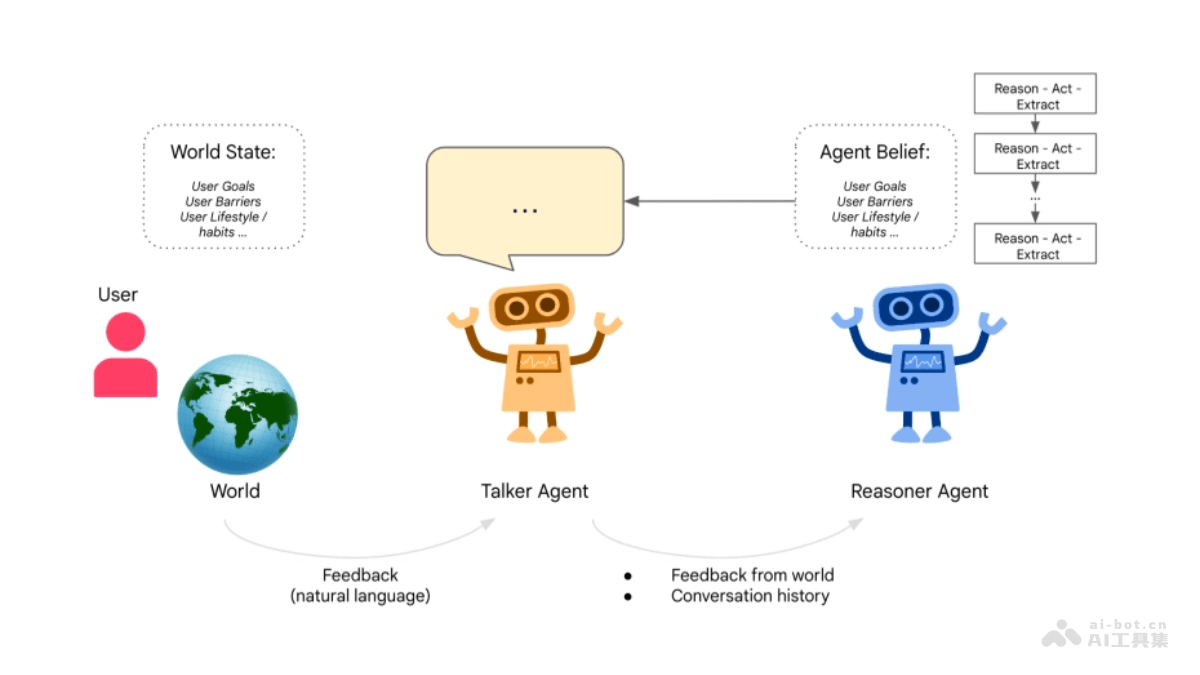
Talker-Reasoner是谷歌DeepMind推出的AI代理架构,借鉴人类的认知理论,将代理分为两个模块:Talker和Reasoner。Talker模拟人类的快速直觉思维(System 1),处理即时对话和反应;Re...
-
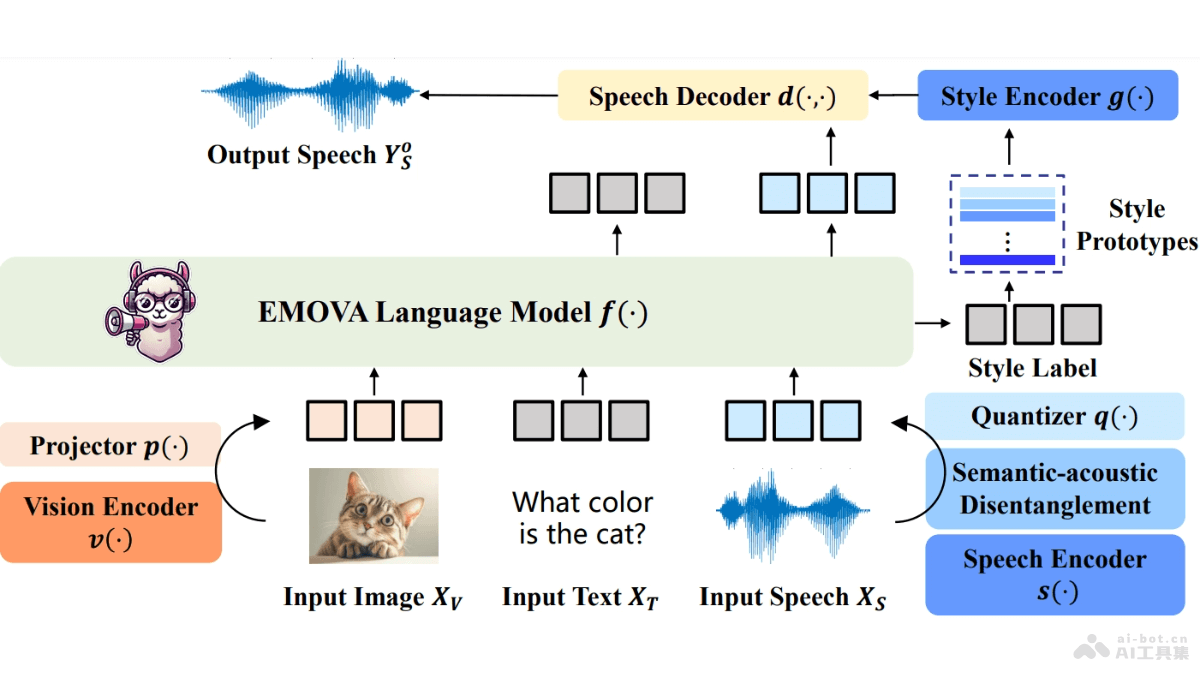
EMOVA(EMotionally Omni-present Voice Assistant)是多模态全能模型,是香港科技大学、香港大学和华为诺亚方舟实验室等机构共同推出的。EMOVA能处理图像、文本和语音模态,实现能看、能...
-

OminiControl是高度通用且参数高效的图像生成框架,为扩散变换器模型如FLUX.1设计,实现对图像生成过程的精细控制。OminiControl支持主题驱动控制和空间控制,例如边缘引导和绘画生成,仅需在基础模型中增加0...
