
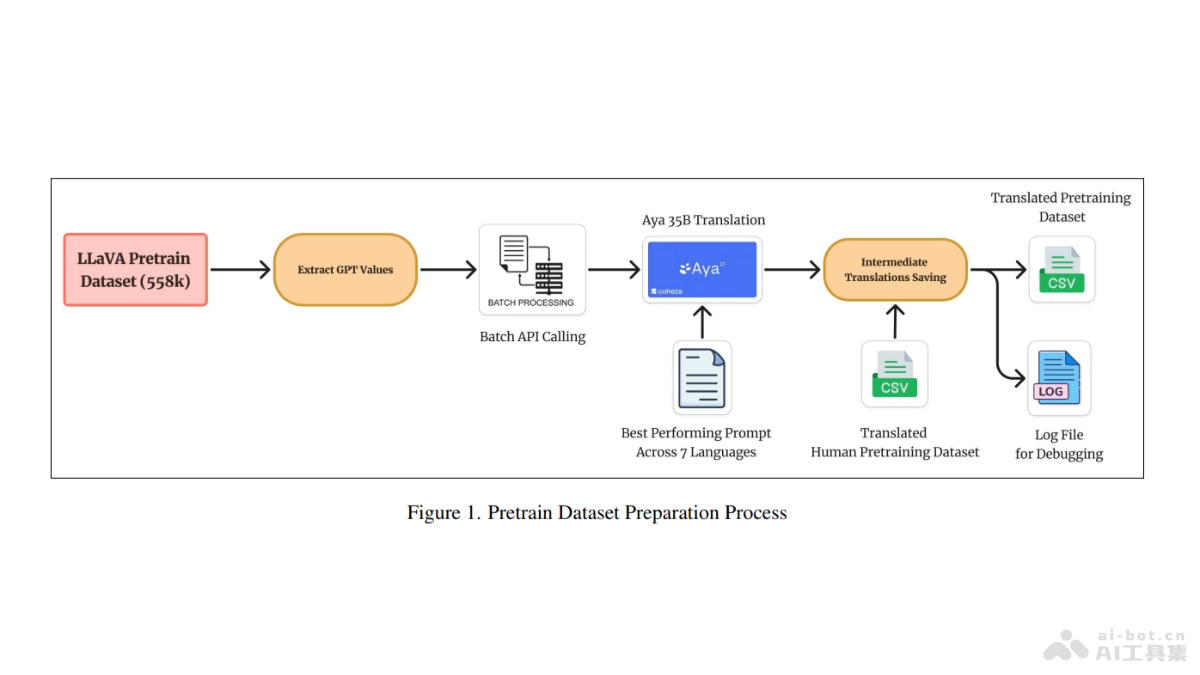
Maya是开源的多语言多模态模型,基于指令微调扩展模型在多种语言和文化背景下的能力。Maya基于LLaVA框架,包含新创建的包含八种语言的预训练数据集,提高视觉-语言任务中的文化和语言理解。Maya基于毒性分析和数据集过滤,...
-
-

Promptic是轻量级的LLM应用开发框架,提供高效且符合Python风格的开发方式。基于LiteLLM,Promptic支持开发者能轻松切换不同的LLM服务提供商,只需更改一行代码。Promptic支持流式响应、内置对话...
-

千影 QianYing是巨人网络推出的有声游戏生成大模型,包含游戏视频生成大模型YingGame和视频配音大模型YingSound。YingGame面向开放世界游戏,是巨人网络AI Lab与清华大学SATLab联合推出的,能...
-

STIV(Scalable Text and Image Conditioned Video Generation)是苹果公司推出的视频生成大模型。STIV拥有8.7亿参数,能处理文本到视频(T2V)和文本图像到视频(TI2...
-

TEN Agent是集成OpenAI Realtime API和RTC技术的开源实时多模态AI代理框架。TEN Agent能实现语音、文本、图像的多模态交互,支持高性能的实时通信,具备低延迟的音视频交互能力。TEN Agen...
-

Project Mariner 是谷歌 DeepMind 推出的浏览器助手。Project Mariner基于 Gemini 2.0 技术,用 Chrome 扩展程序实现浏览器自动化,理解和执行网页任务。Project Ma...
-
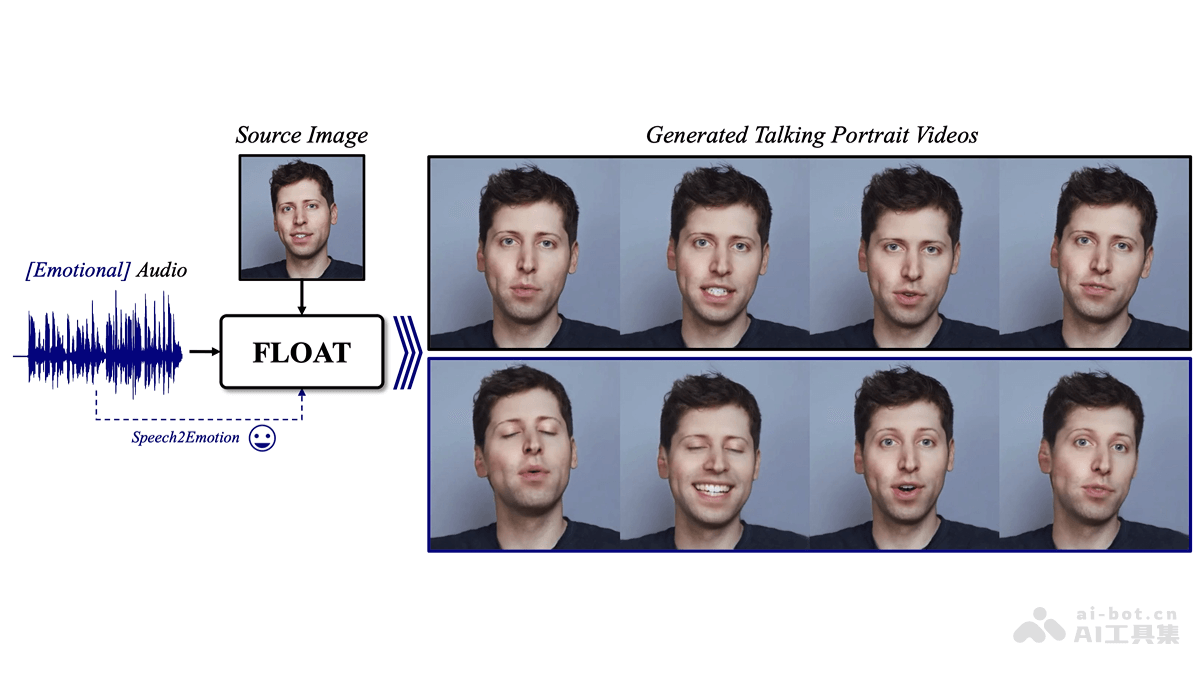
FLOAT是DeepBrain AI 和韩国先进科技研究院推出的音频驱动说话人头像生成模型,基于流匹配生成模型,学习运动潜在空间实现高效的时间一致性运动设计。模型基于Transformer架构的向量场预测器,实现帧间时间一致...
-

MMAudio是先进视频到音频合成技术,基于多模态联合训练,让模型能在广泛的视听和音频文本数据集上进行训练。技术的核心是同步模块,确保生成的音频与视频帧精确匹配,实现高度同步。...
-

Ultravox是新型的多模态大型语言模型(LLM),能直接理解文本和人类语音,无需依赖单独的自动语音识别(ASR)阶段。基于多模态投影器技术将音频数据转换为高维空间表示,与LLM直接耦合,显著减少处理延迟,提高响应速度。...
-

ChatTTSPlus是ChatTTS的扩展版本,基于集成TensorRT加速、语音克隆和移动模型部署等先进技术,提升语音合成的性能和灵活性。在Windows平台上,能实现超过3倍的加速,从28 tokens/s提升到110...
