
Veo 2 是 Google DeepMind 推出的 AI 视频生成模型,能根据文本或图像提示生成高质量视频内容。Veo 2支持高达 4K 分辨率的视频制作,理解镜头控制指令,能模拟现实世界的物理现象及人类表情。Veo 2...
-
-

Megrez-3B-Omni是无问芯穹推出的全球首个端侧全模态理解开源模型,能处理图像、音频和文本三种模态数据。Megrez-3B-Omni在多个主流测试集上展现出超越34B模型的性能,推理速度领先同精度模型达300%。...
-

FreeScale是南洋理工大学、阿里巴巴集团和复旦大学推出无需微调的推理框架,提升预训练扩散模型生成高分辨率图像和视频的能力。FreeScale基于处理和融合不同尺度的信息,有效解决模型在生成超训练分辨率内容时出现的高频信...
-

SnapGen是Snap Inc、香港科技大学、墨尔本大学等机构联合推出的文本到图像(T2I)扩散模型,能在移动设备上快速生成高分辨率(1024x1024像素)的图像,且只需1.4秒。模型用379M参数实现这一性能,显著减少...
-
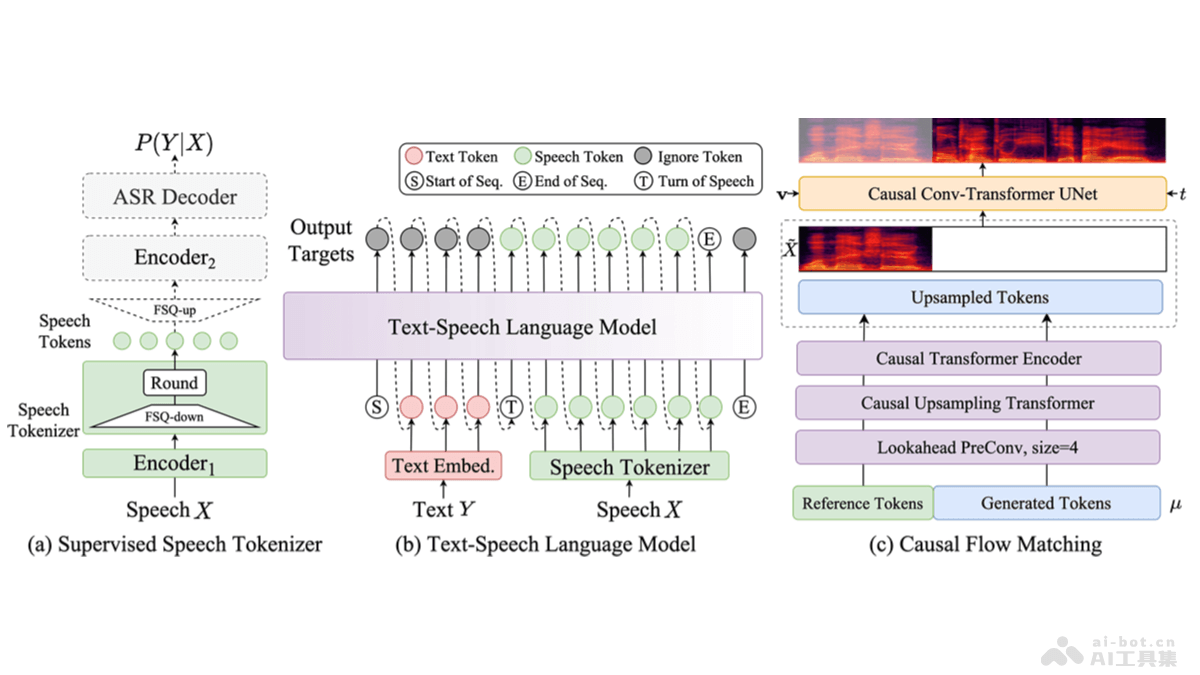
CosyVoice 2.0 是阿里巴巴通义实验室推出的CosyVoice语音生成大模型升级版,模型用有限标量量化技术提高码本利用率,简化文本-语音语言模型架构,推出块感知因果流匹配模型支持多样的合成场景。CosyVoice...
-
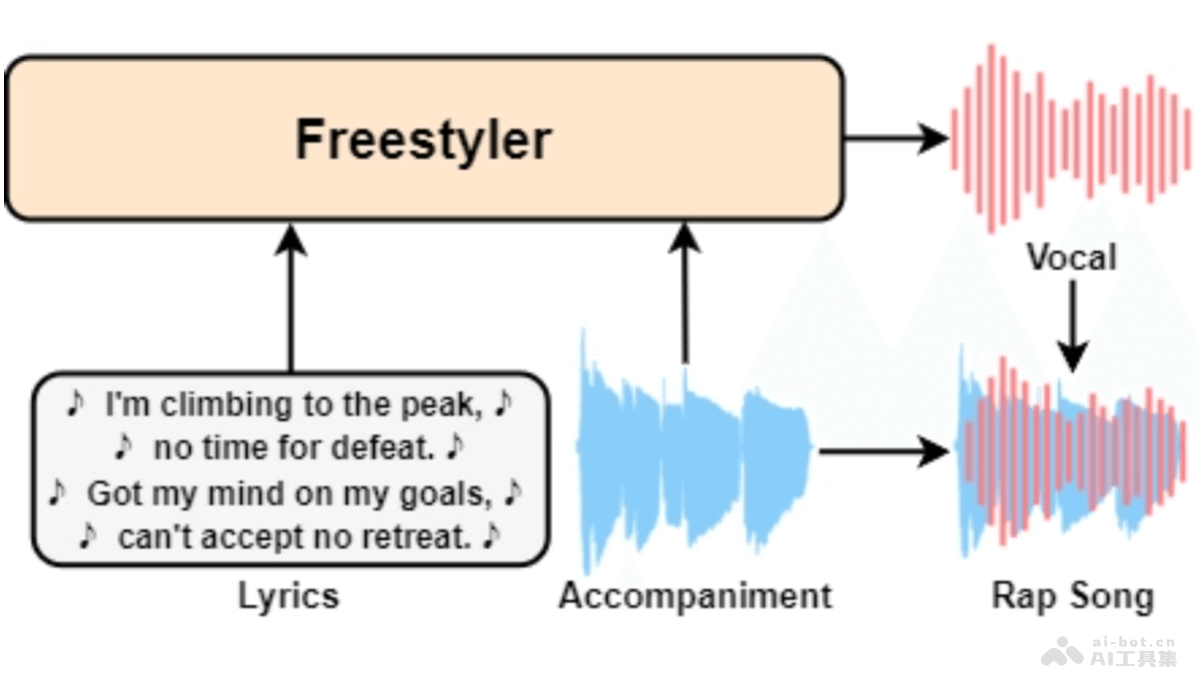
Freestyler是西北工业大学计算机科学学院音频、语音与语言处理小组(ASLP@NPU)、微软及香港中文大学深圳研究院大数据研究所共同推出的说唱乐生成模型,能直接根据歌词和伴奏创作出说唱音乐。...
-

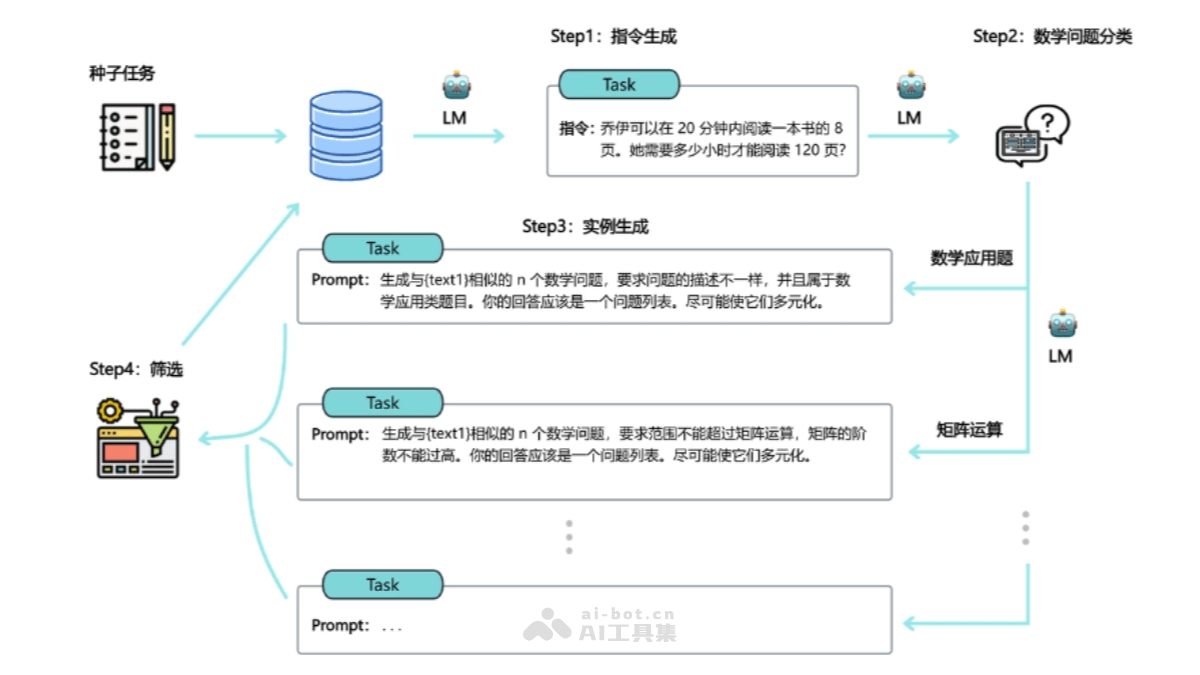
k1 视觉思考模型是kimi推出的k1系列强化学习AI模型,原生支持端到端图像理解和思维链技术,将能力扩展到数学之外的更多基础科学领域。k1模型在图像理解、数学、物理、化学等学科的基准测试中表现优异,超过全球多个标杆模型(如...
-

Step-1o是阶跃星辰推出的国内首个千亿参数端到端语音大模型。模型支持语音、文本等混合形式的输入和输出,可以快速反应并随时打断,提供最便捷的互动体验;同时还可以通过自学和优化来不断进步。...
-

POINTS 1.5 是腾讯微信发布的多模态大模型,是POINTS 1.0的升级版本。 模型继续沿用了POINTS 1.0中的LLaVA架构,由一个视觉编码器、一个投影器和一个大型语言模型组成。 POINTS 1.5在效率和...
-
360gpt2-o1 是 360 自研的 AI 大模型,在推理能力上有显著提升,特别是在数学和逻辑推理任务上表现出色。模型通过合成数据优化、模型后训练和“慢思考”范式实现了技术突破,在多项权威评测中取得了优异成绩。...
