
Vision Search Assistant(VSA)是结合视觉语言模型(VLMs)和网络代理的框架,提升模型对未知视觉内容的理解能力。基于互联网检索,使VLMs处理和回答有关未见图像的问题。VSA在开放集和封闭集问答测试...
网站首页 > AI工具 第17页
-

-

CHANGER是工业级超自然AI换头与色键技术,用在数字内容创作中将演员头部无缝集成到目标身体上,适于视觉特效、数字人类创建和虚拟化身。CHANGER基于色键技术分离背景与前景,用H2增强模拟多样头部形状和发型,及FPAT模...
-

MVDrag3D是创新的3D编辑框架,结合多视图生成和重建先验实现灵活且富有创造性的拖拽编辑。框架用多视图扩散模型作为生成先验,确保在多个渲染视图间进行一致的拖拽编辑,基于重建模型重建编辑对象的3D高斯表示,用视图特定的变形...
-

Vidu 1.5是生数科技推出的AI视频生成平台最新版本,致力于帮助创作者自由表达和高效创作。具备多模态视频大模型,支持参考生视频、图生视频和文生视频,确保角色、物体、场景的一致性。Vidu 1.5能在30秒内生成高清视频,...
-
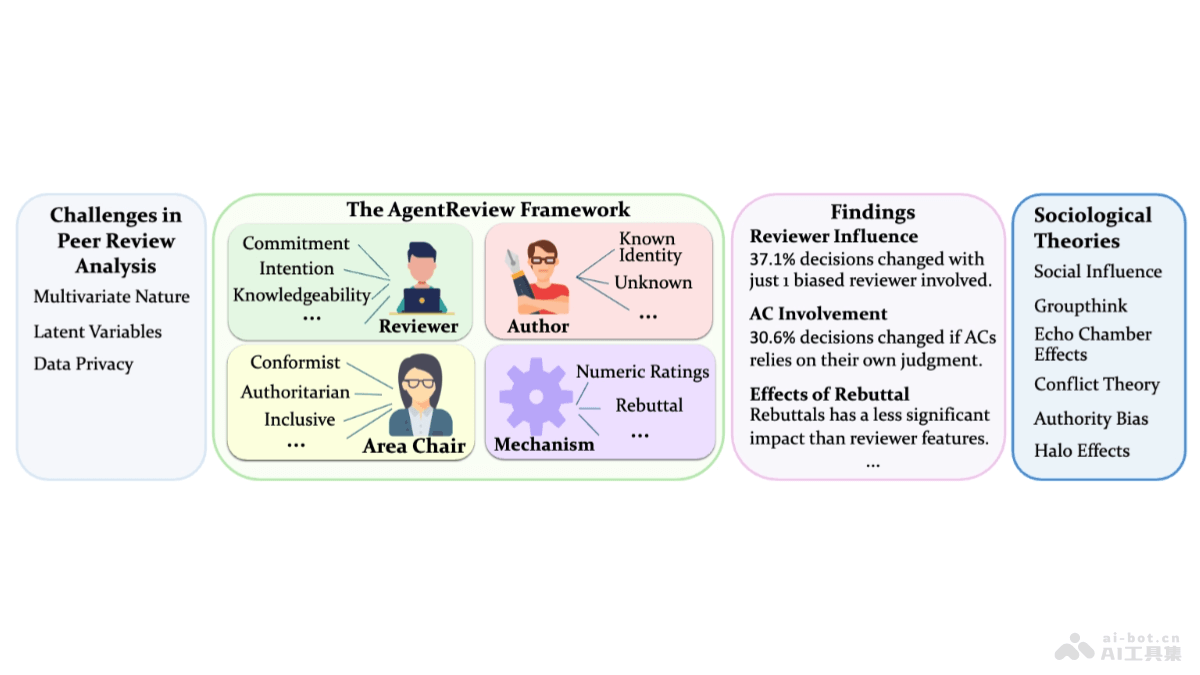
AgentReview是基于大型语言模型(LLM)的框架,模拟学术同行评审过程。AgentReview基于LLM代理模拟评审者、作者和领域主席的角色,支持研究者在尊重隐私的同时,探索评审偏见、角色和决策机制对评审结果的影响。...
-

文心iRAG是百度在2024年百度世界大会上推出的检索增强的文生图技术(iRAG)技术,结合了百度搜索的亿级图片资源和强大的基础模型能力,解决大模型在文生图方面的幻觉问题,提升AI生成图片的真实性和可靠性。基于iRAG技术,...
-

MoneyPrinterTurbo是开源的AI短视频生成工具,能自动化地根据用户提供的视频主题或关键词生成视频文案、素材、字幕和背景音乐,合成高清短视频。工具支持API和Web界面操作,具备自定义文案、多种视频尺寸、批量视频...
-

PDFMathTranslate是开源的PDF文档翻译工具,设计用于翻译科技论文等PDF文件,能保留原文的排版,包括公式和图表。PDFMathTranslate支持双语对照,保持原有目录结构,兼容多种翻译服务,如Google...
-

AlphaFold 3是谷歌DeepMind团队推出的AI模型,能预测蛋白质、核酸(DNA和RNA)、小分子、离子及修饰残基等生物分子的三维结构。模型在结构预测的准确性上取得革命性进展,对药物设计、科研和生物医学领域具有重大...
-

GenXD是新加坡国立大学和微软公司共同推出的3D-4D联合生成框架,能从任意数量的条件图像中生成高质量的3D和4D场景。框架用一个数据整理流程从视频中提取相机姿态和物体运动强度,基于这些信息及大规模4D数据集CamVid-...
